数据库
概述
描述事物的符号记录称为数据,其特点是数据与其语义是不可分的。
四个基本概念
◆数据库(Database,DB):长期储存在计算机内有组织、可共享的大量数据的集合。
◆数据库管理系统(Database ManagementSystem,DBMS):位于用户与操作系统之间的一层数据管理软件。它和操作系统一样是计算机的基础软件,也是一类大型复杂的软件系统。
◆数据库系统(DataBaseSystem,DBS):引入数据库后的计算机系统。一般是指由数据库、数据库管理系统(及其应用开发工具)、应用系统和数据库管理员组成的存储、管理、处理和维护数据的系统。
数据库系统架构图(图源:March)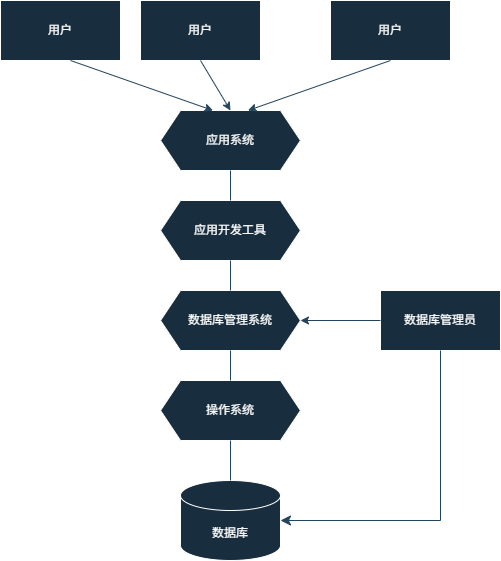
数据库的本质:它是由DBMS创建的逻辑数据集合,没有安装DBMS的话,电脑中不存在可被管理的数据库;只有通过安装的MySQL/Oracle这种软件,才能在电脑的存储介质(硬盘、内存)上创建、存储和维护数据库。
一句话:先装MySQL(DBMS),再用它创建数据库,数据库是DBMS运行后产生的产物,而非电脑自带的内容。
数据管理技术
数据管理是指对数据进行分类、组织、编码、存储、检索和维护。
数据管理技术发展历程:人工管理阶段->文件系统管理阶段->数据库系统阶段
数据库系统的特点:
(1)数据结构化
(2)数据的共享性高,冗余度低且易扩充
(3)数据独立性高(当数据的物理存储、逻辑结构改变了,应用程序不用改变。)
(4)数据由数据库管理系统统一管理和控制(以保证数据的完整性和安全性,并在多用户同时使用数据库时进行并发控制,在发生故障后对数据库进行恢复。)
数据库出现后:
◆以加工数据的程序为中心->以共享数据库为中心;
◆以软件为中心->以数据为中心。
数据模型
按照数据建模的过程可以把模型划分为概念模型和数据模型。
◆概念模型是按用户的观点来对数据建模。它用于信息世界的建模。
概念模型的一种表示方法:实体-联系模型(E-R模型)
两个实体型之间的三类联系:
①一对一联系(1∶1)
②一对多联系(1∶n)
③多对多联系(m∶n)
◆数据模型是按计算机系统的观点对数据建模 ,用于DBMS实现。
数据模型三要素:数据结构、数据操纵、完整性约束。
数据模型分为两类:逻辑模型、物理模型
◆逻辑模型主要包括层次模型、网状模型、关系模型、面向对象数据模型、对象关系数据模型、半结构化的XML数据模型等。
◆物理模型是对数据最底层的抽象 ,描述数据在系统内部的表示方式和存取方法 ,在磁盘或磁带上的存储方式和存取方法。
层次模型:树的形式组织数据
网状模型:图的形式组织数据
关系模型:表的形式组织数据
关系模型的数据结构:
(1)关系:一个关系对应通常说的一张二维表。
(2)元组:表中的一行即为一个元组。
(3)属性:表中的一列即为一个属性,给每一个属性起一个名称即属性名。
(4)主码:也称码键。表中的某个属性组,它可以唯一确定一个元组。
(5)域:一属性的取值范围。例如,性别的域是(男,女)。
(6)分量:元组中的一个属性值。
(7)关系模式:对关系的描述,一般表示为:关系名(属性1,属性2,…,属性n)。
数据库系统的三级模式结构
数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三级构成。
数据库系统的三级模式是对数据的三个抽象级别,这三级模式之间还提供了两级映像,即外模式/模式映像、模式/内模式映像,保证了数据库系统中的数据能够具有较强的逻辑独立性和物理独立性。
各人员的数据视图: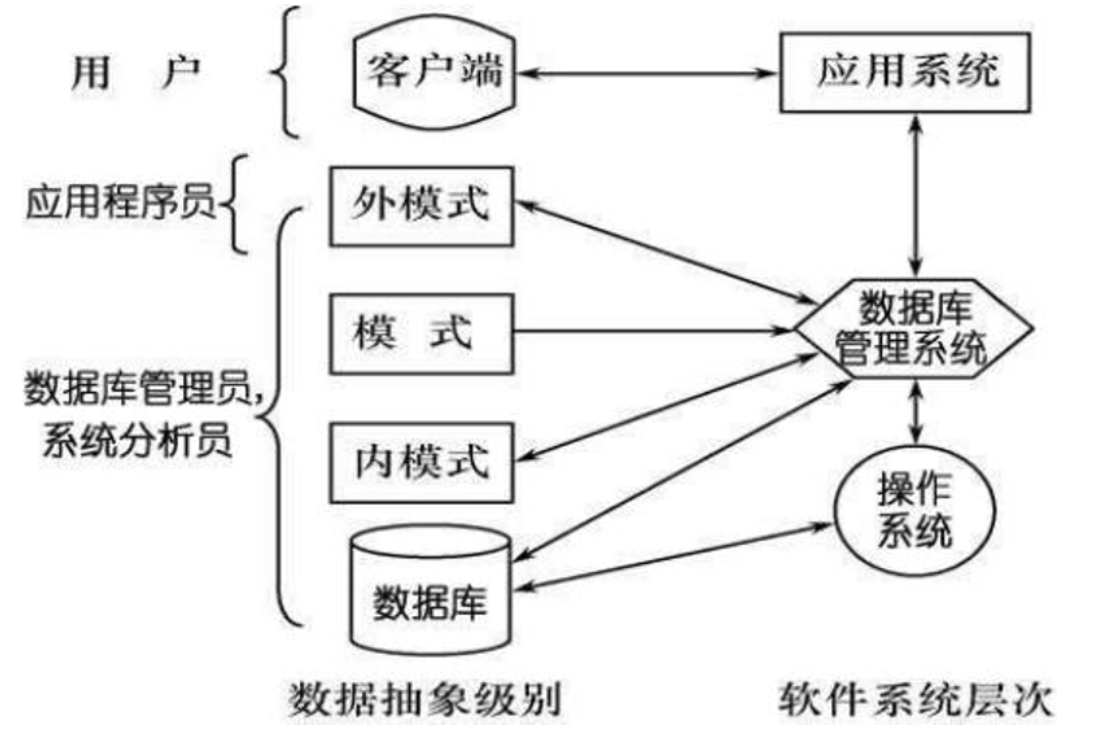
关系数据库
域是一组具有相同数据类型的值的集合。
笛卡尔积是域上的一种集合运算。
码是一个属性或多个属性,有特殊的性质。
(1)若关系模式中的某一个属性或一组属性的值能唯一地标识一个元组,而它的真子集不能唯一地标识一个元组,则称该属性或属性组为候选码(candidate key)。
(2)若一个关系有多个候选码,则选定其中一个为主码(primary key),或称主键。
(3)候选码的诸属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性。
(4)所有字段加起来才是唯一标识的叫做全码。
关系操作包括查询和更新操作。
◆查询操作:选择、投影、连接、除、并、差、交、笛卡尔积。
◆数据更新:插入、删除、修改。
选择、投影(选出需要的列)、并、差、笛卡尔基是5种基本操作。
关系模型中的三类完整性约束:实体完整性、参照完整性、用户定义的完整性。
◆实体完整性约束的是表的主键,主键字段不能重复、不能为 NULL。
◆参照完整性约束的是外键,保证 “子表的外键值必须是父表主键已存在的值,或为 NULL”。
◆用户定义的完整性是根据具体业务需求自定义的约束,既不是主键也不是外键,而是针对字段的“业务规则”。
关系代数
关系代数是一种抽象的查询语言,它用对关系的运算来表达查询。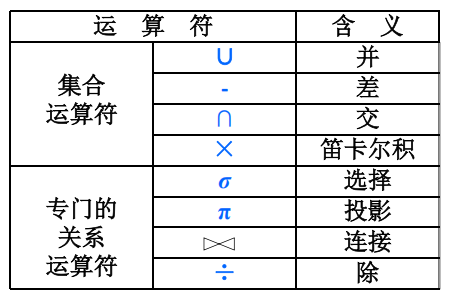
◆R×S 笛卡尔积
列:(n+m) 列元组的集合
行:k1×k2个元组
◆选择
例1:请写出对应的关系代数,查询信息系(IS系)全体学生。σSdept = ‘IS’ (Student)
例2:请写出对应的关系代数:查询年龄小于20岁的学生。σSage < 20 (Student)
◆投影是从列的角度进行的运算,即从垂直方向进行抽取。
例:查询学生的姓名和所在系,请写出对应关系代数。πSname,Sdep (Student)
◆连接也称为 θ 连接,接是将关系R和关系S按相应属性值的比较条件连接成一个新的关系,它是R与S的笛卡尔积的一个子集。
等值连接、自然连接、外连接(外连接、左外连接、右外连接)。
◆除
除操作是同时从行和列角度进行运算。(涉及象集)
关系数据库标准语言SQL
| SQL功能 | 动词 |
|---|---|
| 数据定义 | create、drop、alter |
| 数据查询 | select |
| 数据操纵 | insert、update、delete |
| 数据控制 | grant、revoke |
创建表
1 | show databases; |
Char(n):定长存储,n<255。
Varchar(n):不定长存储(按实际长度存储),长度最大不超过n 。
◆约束
主键约束 、非空约束、唯一性约束、检查约束、默认约束。
1 | create table Student |
一个表只能有一个字段使用auto_increment约束,且该字段必须设置为主键。
为已有的表添加外键约束 foreign key:alter table 从表名 add constraint 外键名 foreign key(从表的外键字段名) references 主表名 (主表的主键字段名)
删除外键约束 foreign key:alter table 从表名 drop foreign key 外键名
修改基本表
1 | alter table<表名> |
◆修改表名:alter table stu1 rename (to) stu2;
◆修改字段名和数据类型:ALTER TABLE 表名 change 旧字段名 新字段名 新数据类型;
◆修改字段名:alter table 表名 modify 字段名 新数据类型;
◆修改字段的排列位置:alter table 表名 modify 字段名1 新数据类型 first|after 字段名2;
◆添加字段:alter table 表名 add 新字段名 数据类型 [约束条件][FIRST|AFTER已经存在的字段名];
◆删除字段:alter table 表名 drop 字段名;
查询
基础查询→条件查询→多表关联→进阶查询
1 | select 要查询的字段/表达式 |
基础查询
◆用*代表“所有字段”,适合快速预览表数据,但生产环境尽量不用(性能差)。
◆用 AS 给字段 / 表名起别名。
◆用 distinct 去除查询结果中的重复行。
1 | -- 查询Student表中所有学生的所有信息 |
条件查询
用 WHERE 筛选符合条件的行,是查询的核心技巧,常用条件运算符如下:
| 运算符 | 作用 | 示例 |
|---|---|---|
= |
等于 | Ssex = '男' |
!=/<> |
不等于 | Sdept <> '计算机系' |
>/< |
大于 / 小于 | Sage > 20 |
>=/<= |
大于等于 / 小于等于 | Sage <= 22 |
BETWEEN...AND... |
区间(闭区间) | Sage BETWEEN 18 AND 22 |
IN(值1,值2) |
匹配多个值 | Sdept IN ('计算机系','数学系') |
LIKE |
模糊匹配 | Sname LIKE '张%' |
IS NULL |
为空 | Cpno IS NULL |
IS NOT NULL |
不为空 | Grade IS NOT NULL |
AND/OR |
多条件(且 / 或) | Ssex='女' AND Sage>20 |
例: 查询订单中支付手段为“微信、支付宝、网银“的订单信息。
1 | SELECT |
排序查询
用 ORDER BY 对查询结果排序,默认升序(ASC),降序用 DESC。
1 | -- 1. 按学生年龄升序排列(从小到大) |
例: 查询每种支付手段的订单的最高订单金额、最低订单金额和平均订单金额。
1 | SELECT vPayType, MAX(mTotalCost) AS '最高订单金额', MIN(mTotalCost) AS '最低订单金额', AVG(mTotalCost) AS '平均订单金额' FROM orders GROUP BY vPayType; |
这里要注意还要查询vPayType,否则不会显示是哪一种支付手段。
聚合查询
用聚合函数对数据做统计,常用聚合函数。
| 函数 | 作用 | 示例 |
|---|---|---|
COUNT(*) |
统计行数 | COUNT(*)(所有行) |
COUNT(字段) |
统计非空行数 | COUNT(Grade)(成绩非空的行数) |
SUM(字段) |
求和 | SUM(Ccredit)(总学分) |
AVG(字段) |
平均值 | AVG(Grade)(平均成绩) |
MAX(字段) |
最大值 | MAX(Grade)(最高成绩) |
MIN(字段) |
最小值 | MIN(Grade)(最低成绩) |
1 | -- 1. 统计学生总数 |
◆where与having的区别:
| 对比维度 | WHERE | HAVING |
|---|---|---|
| 筛选时机 | 分组(GROUP BY)之前 | 分组(GROUP BY)之后 |
| 筛选对象 | 原始行数据(单条记录) | 分组后的聚合结果(统计值) |
| 能否用聚合函数 | ❌ 不能(比如不能写 WHERE AVG(Grade)>60) |
✅ 能(比如 HAVING AVG(Grade)>60) |
| 适用场景 | 筛选单条记录的条件(比如 “学号 = 001”“金额 > 0”) | 筛选分组统计的条件(比如 “平均成绩> 60”“订单数≥5”) |
| 语法位置 | 必须在 FROM 之后、GROUP BY 之前 |
必须在 GROUP BY 之后 |
连接查询
实际开发中,数据分散在多张表,需要通过关联字段(外键) 拼接查询,核心是 JOIN。
| 关联类型 | 作用 | 语法 |
|---|---|---|
| 内连接(INNER JOIN) | 只查两表匹配的数据 | A JOIN B ON A.字段=B.字段 |
| 左连接(LEFT JOIN) | 查左表所有数据,右表匹配不到则为 NULL | A LEFT JOIN B ON A.字段=B.字段 |
| 右连接(RIGHT JOIN) | 查右表所有数据,左表匹配不到则为 NULL | A RIGHT JOIN B ON A.字段=B.字段 |
1 | -- 1. 内连接:查询学生的姓名、修课的课程名、成绩(只查有成绩的) |
嵌套查询
1 | SELECT Sno |
可以用 = 代替IN
1 | SELECT Sno, Cno |
◆ANY
①使用关键字ANY时,只要满足内层查询语句返回的结果中的任何一个,就可以通过该条件来执行外层查询语句;
② 关键字ALL刚好相反,只有满足内层查询语句的所有结果,才可以执行外层查询语句。
例:查询其他系中比计算机科学某一学生年龄小的学生姓名和年龄。
1 | SELECT Sname, Sage |
!=(或<>)ANY 不等于子查询结果中的某个值
◆EXISTS
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false” 。
例:查询所有选修了1号课程的学生姓名。(用嵌套查询)
1 | SELECT Sname |
理解:如果子查询能查到至少 1 条记录,等到遍历完所有学生,最终主查询返回所有 “验证为真” 的学生姓名。
数据更新
插入数据
◆插入元组
例:将一个新学生元组(学号:200215128;姓名:陈冬;性别:男;所在系:IS;年龄:18岁)插入到Student表中。
1 | INSERT INTO Student (Sno, Sname, Ssex, Sdept, Sage) |
◆插入子查询结果(可以一次插入多个元组)
例:对每一个系,求学生的平均年龄,并把结果存入数据库。
1 | 第一步:建表 |
修改数据
UPDATE <表名> SET <列名>=<表达式>[WHERE <条件>];
删除数据
DELETE FROM <表名> [WHERE <条件>];
索引
根据索引的类型普通索引、唯一索引(允许字段为NULL)、复合索引、主键索引、全文索引等。
◆建立索引:create unique index idx_student_sno on Student(Sno);
主键字段会自动生成主键索引,若创建表时未指定主键,也可通过以下方式添加(本质是给主键加索引):
1 | -- 方式1:创建表时指定主键(自动生成主键索引) |
◆删除索引:drop index <索引名>
什么情况下,我们会考虑给字段添加索引呢?数据量庞大
视图
视图的作用:
- 简化复杂查询:把多表关联、分组统计等复杂 SQL 封装成视图,后续查数据只需
SELECT * FROM 视图名,不用重复写复杂 SQL; - 数据安全:可以只给用户暴露视图(比如只显示学生姓名、系别,隐藏年龄、电话等敏感字段),不直接暴露源表;
- 数据抽象:屏蔽表结构的细节,用户只需关注需要的字段,不用关心底层表的关联逻辑。
①虚表,是从一个或几个基本表(或视图)导出的表;
②只存放视图的定义,不存放视图对应的数据;
◆创建视图:create view <视图名> AS <子查询> [with check option];
◆删除视图:DROP VIEW <视图名>;
权限
在MySQL中使用GRANT关键字为用户设置权限。只有拥有GRANT权限,才能执行GRANT语句。
全部权限:all priviliges
所有用户:public
所有数据库:*.*
March数据库的Student表:March.Student
例1(权限授予):把查询Student表权限授给用户U1。
1 | grant select on Student to U1; |
例2(传播权限):把查询Student表和修改学生学号的权限授给用户U4 ,并允许他再将此权限授予其他用户。
1 | grant update(Sno), select on Student to U4 with grant option; |
例3(查看权限):查看tom用户的权限。
1 | show grant for 'tom'@'localhost'; |
例4(创建登录用户、收回权限):创建用户cuit,密码123456。现有数据表books,将所有权限赋给用户CUIT。然后收回insert 权限。
1 | create user 'cuit'@'localhost' identified by '123456'; |
例5(修改用户名和密码,删除用户):修改用户账号tempuser的密码为123456。修改普通用户U1的用户名为U2。最后删除U2。
1 | SET PASSWORD FOR tempuser@localhost= '123456'; |
视图+授权:常用的安全性控制方法
断言
断言是数据库级别的自定义完整性约束,作用是强制整个数据库(或多个表)满足某个业务规则 —— 它和CHECK约束的核心区别是:
◆CHECK:只约束单个表的字段 / 行数据;
◆断言:可约束多个表之间的关联规则(也可约束单表),是更通用、更强大的完整性规则。
创建断言:create assertion <断言名> check(约束规则);
删除断言:drop assertion <断言名>
例:要求任意学生的选课门数不能超过 5 门(涉及 Student 和 SC 表关联):
1 | CREATE ASSERTION Assert_Max_Course |
理解:如果有学生选课数超过 5 门,断言约束失败,数据库会拒绝导致该结果的操作(比如插入第 6 门选课记录)。
| 维度 | 断言(Assertion) | CHECK 约束 |
|---|---|---|
| 作用范围 | 数据库级(多表 / 单表) | 表级(仅当前表) |
| 约束对象 | 可关联多个表的规则 | 仅当前表的字段 / 行 |
| 语法灵活性 | 支持复杂子查询、聚合函数 | 仅支持单表行级逻辑(部分数据库不支持子查询) |
| 数据库支持 | 仅部分数据库支持(如 Oracle),MySQL 不支持 | 大部分数据库支持(MySQL 8.0 + 生效) |
| 性能 | 开销高(需检查全库数据) | 开销低(仅检查当前行) |
触发器
触发器是数据库自动执行的一段 SQL 逻辑,当对表执行INSERT/UPDATE/DELETE操作时,触发器会被 “触发”,自动执行预设的 SQL 语句。
例:假设我们有一个 orders 表,我们希望在订单状态更新时,将状态变化记录到 order_logs表中。
1 | delimiter // |
NOW()是MySQL 内置函数,获取当前系统时间(作为日志的 “状态变更时间”);
MySQL 不允许直接修改现有的触发器。如果需要修改触发器,通常的做法是先删除旧触发器,然后重新创建一个新的触发器。
数据库设计
关系模式由五部分组成,是一个五元组:R(U, D, DOM, F)。其中R是关系名,U是属性集,D是域集,DOM是映射,F是函数依赖。三元组:R<U,F>。
◆完全依赖:(Sno, Cno) → Grade(成绩完全依赖于 “学号 + 课程号”,只知道学号或只知道课程号,都无法确定成绩)。
◆部分依赖:(Sno, Cno, Sname)(姓名只依赖于学号,不依赖于课程号,属于 “部分依赖”)—— 这是设计表时要避免的(违反第二范式)。
◆传递依赖:Sno → Sdept,Sdept → Dname(系名),则Sno → Dname(系名传递依赖于学号)—— 违反第三范式,也是设计时要避免的。
在关系型数据库中,关于数据表设计的基本原则、规则就称为范式。
- 第一范式(1NF):要求任何一张表必须有主键,每一个字段原子性不可再分。
- 第二范式(2NF):要求所有非主键字段完全依赖主键,不要产生部分依赖。
- 第三范式(3NF):要求所有非主键字段直接依赖主键,不要产生传递依赖。
第三范式(3NF)通常被认为在性能、拓展性和数据完整性方面达到了最好的平衡。数据库设计最重要的是看需求跟性能,需求性能>表结构。所以不能一味的去追求范式建立数据库。
- 巴斯范式(BCNF)
- 第四范式(4NF)
- 第五范式(5NF ,又称完美范式), 级别最高。
越⾼的范式数据库冗余越⼩。按照以上范式设计数据库表,可以避免表中数据的冗余,空间的浪费。
◆数据库设计的基本步骤: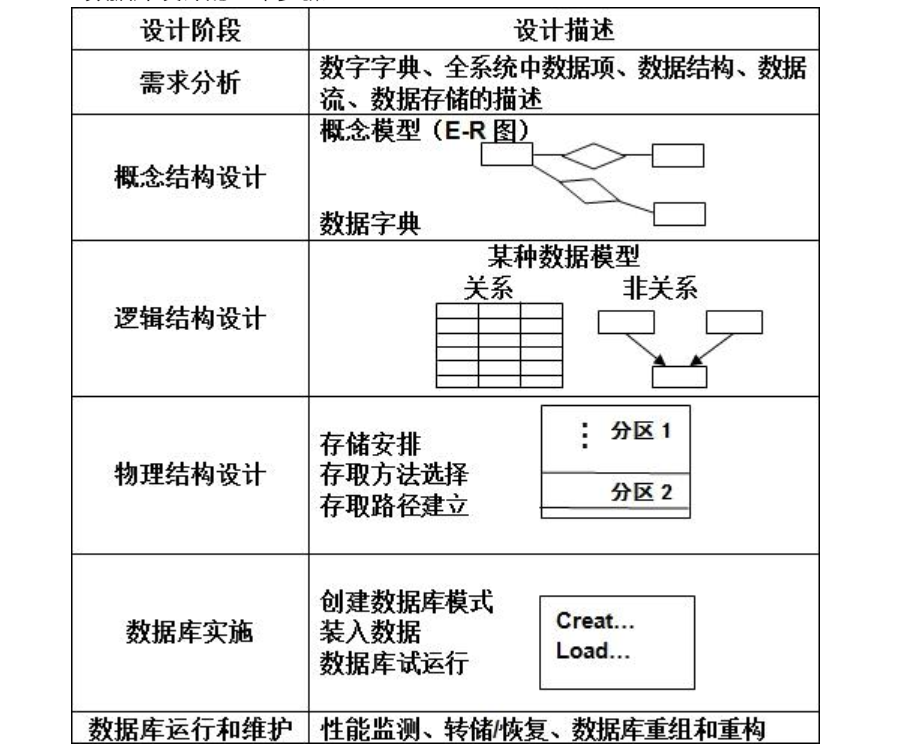
◆存储过程是数据库中预编译、可重复执行的 SQL 代码块,可以理解为数据库层面的“函数”或“脚本”——它将一组复杂的 SQL 操作(查询、插入、更新、删除、循环、判断等)封装成一个命名实体,存储在数据库服务器中,后续通过“调用”即可重复执行,无需每次重新编写完整 SQL。
创建存储过程:
1 | DELIMITER // |
显示存储过程状态信息:show procedure status like ‘COMPAR’;
显示存储过程创建信息:show create procedure COMPAR;
要声明局部变量必须使用declare语句。局部变量必须在存储过程的开头就声明,声明完后,可以在声明它的BEGIN…END语句块中使用该变量,其他语句块中不可以使用它。
游标是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标用于对查询数据库所返回的记录进行遍历时,游标充当指针的作用,一次只指向一行,而通过控制游标的移动,能遍历结果中的所有行,以便进行相应的操作。
◆声明游标:declare 游标名称 cursor for 结果集(select语句)
◆打开游标:OPEN 游标名称
◆提取数据:FETCH 游标名称 INTO 变量列表
◆关闭游标:CLOSE 游标名称
 wechat
wechat


